

对于人工智能,人类向来保持着“期待和担忧各半”的态度。
已故物理学家斯蒂芬·霍金曾经这样评价人工智能,“人工智能可能是人类历史上最大的发明。”但是他同时强调,“它可能带来无限的好处,但也可能是我们的末日。”
霍金的这句话,表达了人们对人工智能带来的巨大潜力和威胁的“双重感情”。

现阶段,人工智能还处在爆发的前夜,但也展现出巨大的成长潜力。
窥一斑而知全豹,随着OpenAI推出Sora、谷歌发布Gemini1.5Pro,在2024年,人工智能会如何影响媒体、广告、乃至智能汽车行业呢?

2月16日,OpenAI宣布推出全新的生成式人工智能模型Sora。
对此,多家券商评价到,AI视频生成迎来里程碑时刻。
招商证券说,Sora将推动AI视频生成进入一个全新的时代。华泰证券的报告说,视频AI进入大规模应用的前夜。天风证券的报告说,下一个亿级用户的互联网平台雏形已然出现。

Sora的工作原理类似DALL-E:用户输入想要的场景,Sora即可返回一个高清视频片段。此外,Sora还可根据静态图像拓展现有视频或填充缺失的帧。
与Runway Gen2、Pika等文生视频模型相比,Sora主要实现了以下突破:
- 视频时长达到60秒:Sora可以通过文本指令直接输出长达60秒的视频,并保持视频主体与背景的高度流畅性与稳定性。
- 文本的深度理解能力:Sora可以准确理解用户的文本指令,无论是复杂的动作场景还是细腻的情感表达,Sora都能够精确捕捉并展现。
- 对真实世界的理解:Sora对物理规律的遵循程度较高,对于光影反射、运动方式、镜头移动等细节的呈现效果较为逼真。
- 长序列连贯性和目标持久性:Sora能在单个视频中生成同一角色的多个镜头,并在整个视频中保持其外观。
- 即使人、动物和物体被遮挡或离开画面,Sora模型也能使其保持不变。

另外,Sora表现出了良好的多模态能力。
其一、Sora不仅支持文本生成视频,还能够根据提供的图片作为输入来生成视频。
其二、Sora还能够扩展生成的视频,在时间上向前或向后扩展,并具有连接视频等视频编辑的能力。
其三、Sora还有生成图像的能力,Sora可以生成不同尺寸大小的图像,分辨率最高可达2048X2048的水平。
这意味着,只要你的要求提得足够清晰,且视频长度在60秒以内,那么Sora几乎可以零成本地执行你的所有设计。

OpenAI将Sora定位为模拟世界的视频生成模型,能够模拟真实世界运行的规律。这也是多家券商高度评价Sora的原因所在。
同期,谷歌宣布了下一代大模型Gemini 1.5 Pro。Gemini1.5 Pro将上下文窗口长度扩展到100万个tokens,实现了迄今通用大模型最长的上下文窗口。
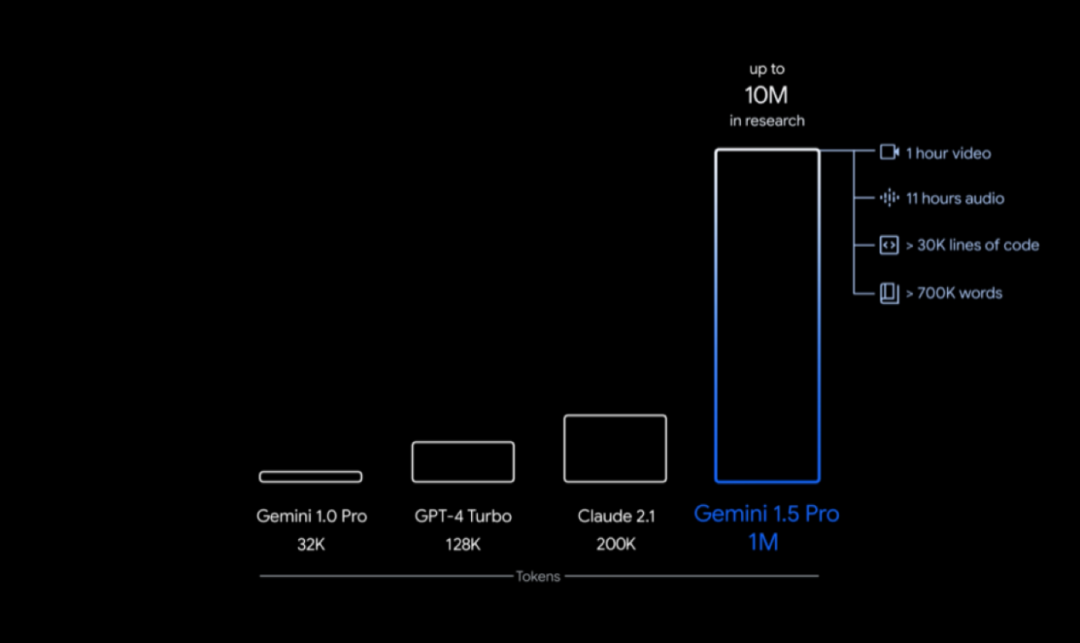
这意味着使用1.5Pro能够一次性处理海量信息,比如1小时的视频、11小时的音频、超过30,000行的代码库,或是超过700,000个单词。
一种是AI视频大模型,一种是通用大模型,两者先后发布必定不是巧合。
GPT-4已经激起了普通人投身AI领域的热情,Gemini则展现出后发制人的潜力。不难想象,在Sora之后,谷歌也会推出自己的AI视频模型。毕竟,3D、视听等多模态模型仍是一片蓝海。
GPT-4和Gemini,就像一对双子星,在通用大模型和细分领域大模型之间不断展开竞争,也将持续促进乃至颠覆行业的认知。

虽然目前Sora存在一定的局限性,诸如无法准确模拟常见的物理运动过程,视频互动中无法正确显示物体状态的变化、长时间样本发展的不连贯性或物体突然出现等等。

但Sora所呈现的效果,所支持的视频参数等基础条件,让所有人在Sora发布的72h内,已经形成了一种共识:Sora已具备商用化技术基础,AI视频商用不再遥远。
我们可以看到ChatGPT的出现,已经大大提高了生产率:
GitHub、Copilot和Replit AI等编程助手已获得了一定成果,它们的出现提高了软件开发人员的工作效率和工作状态。
文生图的大模型飞速发展也重塑了平面设计,图像模型的输出效果已可与专业平面设计师媲美。

创作文字的成本正急剧下滑,在过去的一个世纪中,撰写书面内容的成本按实际价值计算相对稳定。但在过去两年中,随着大语言模型写作质量的提高,成本也随之下降。
我们有理由相信,文生视频大模型的出现,可以让视频成本无限压缩,颠覆动画师的工作方式,让更多的导演排出《繁花》里那种看起来很有意境的氛围。
除了颠覆影视业,Sora或在自动驾驶上大有可为。
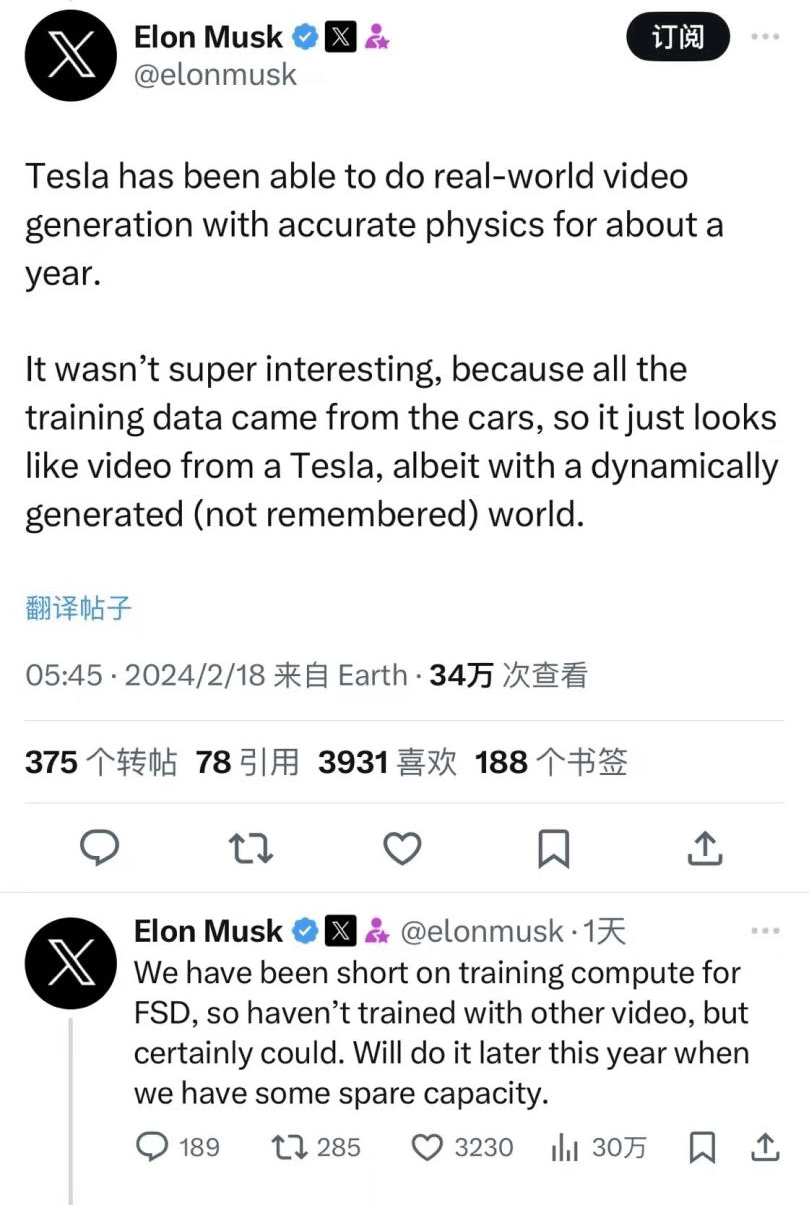
近期,马斯克也在力证特斯拉在视频生成上的实力,“特斯拉在大约一年前就能以精确的物理生成真实世界的视频。只不过,由于训练数据来自汽车,生成的视频并不有趣。这些视频看起来像特斯拉的普通视频,实际上是通过动态生成的。”
中信证券在研报中称,在技术上,Sora采用了Diffusion Transformer的路线。OpenAI表示,Sora在训练过程中表现出了与其他模型不同的涌现能力,通过涌现学习到了物品的时间与空间的相关性以及与周围世界的互动能力等等。
比如,Sora有时能够以一些简单的方式模拟现实世界的状态。比如,画家可以在画布上留下新的笔画,并且这些笔画随着时间的推移会持续存在。再比如,视频中人可以吃汉堡并在汉堡上留下咬痕。
如上文所述,Sora可以成为真正的“世界模型”。

360董事长周鸿祎也表示,“原来的自动驾驶技术过度强调感知层面,而没有工作在认知层面。其实人在驾驶汽车的时候,很多判断是基于对这个世界的理解。比如对方的速度怎么样、能否发生碰撞、碰撞严重性如何。”
我们可以畅想这样几个场景:
Chatgpt大模型可以给Sora下达生成视频的指令,并且其可以根据人类最初的输入来实现指令的不断进阶。
Sora大模型可以根据文本、图片,乃至视频生成自动驾驶的模拟世界,训练现有的自动驾驶感知决策模型,甚至可以把互动的能力加成给现有模型。

当下,有些车企采用的九轴模拟器,在实现底盘调校的同时,也在训练自动驾驶模型。Sora的出现,将跳出传统地图建模的场景,大大提升训练的效率。
而在智能座舱层面,Sora将把文本、2D的大模型交互形式升维成3D,用户可以随时生成一段视频,甚至将沿途拍摄的视频在线实时剪辑,诸如智己已经开始将AI技术用于增强摄像头感知画面画质。

我们不妨再展望一下,AI对自动驾驶的加成,加上电池技术的进步,可以促使自主移动设备(比如自动驾驶出租车)的规模化。
而Robotaxi规模化的前提则是,补能的自动化。也许是换电,也是补能机器人(或机器手)。
环环相扣,AI缔造的智能世界,也许并不遥远。