
理想汽车,应该是苹果、特斯拉的“大型信徒”。
这句话,有那么一点武断,但理想汽车在智能驾驶发布会上的“操盘”,确实更有科技公司的风格,甚至还做了一些颇为“本土化”的适配。
不得不说,它是会“讲故事的”。


前面的一通感慨,只是想证明一件事,理想汽车的传播上有自己的章法,尤其擅长抢占稀缺的认知高度,“别人没做的,或者还没做明白的,它要抢着来,占到1号位”。
最典型的一个例子,行业里人人都在讲“端到端”,但如此近距离给用户讲“端到端”的,还真没有先例。特斯拉曾经讲过,但那是英文,在国内的传播度有限。
其实,不论是否真的讲明白了,有时候,抢先做出细致科普的动作,都会让C端用户刮目相看。

言归正传,我们先来说说,“7月全量推送无图NOA”这件事。
目前,无图NOA是一个大趋势。因为丢掉高精地图,拒绝先验信息,该智驾系统的可用覆盖范围会更广。毕竟,高精地图的覆盖和维护需要比较大的成本。
另外,原本借助高精地图,于智驾车辆而言,更像在“高铁的轨道”上行驶,执行难度会降低很多,但处理未知情况的能力,则大打折扣。

那么,要做到“无图”,具体要攻克哪些难关?
1、感知能力不仅要强,还要具备道路结构的构建能力。高精地图,相当于提前搭建了道路的立体信息。只要定位准,车辆完全清楚接下来的道路是怎么回事。但高精地图基本不会去覆盖胡同窄路、乡村小路,所以,“全国都能开”是受限制的。如果系统像人一样可以脑部道路结构,那其适应性就很强了。
2、对障碍物绕行和避让的决策要更加丝滑,这对时空联合规划能力提出了一定的要求,要能够持续预测自车与他车的空间交互关系,并规划出所有可行驶轨迹,并且果断而安全地执行绕行动作。
3、对城市复杂路口的“博弈思考”提出挑战,具体采用了BEV视觉模型,再融合导航匹配算法,能够实时感知变化的路沿、路面箭头标识和路口特征,并将车道结构和导航特征充分融合,让路口同行更稳定。
4、对异形障碍物的识别要求更高,可以借助激光雷达与视觉前融合的占用网络,让车辆识别更大范围内的不规则障碍物,从而对其他交通参与者的行为实现更早、更准确的预判。
其实,我们会发现一个事实。当“无图”目标被提出来之后,会有更多先进的算法、模型被引入,有很多难题反而迎刃而解了。本质上,是因为智驾技术上了一个新台阶,高精地图才有机会被丢掉了。

还有一个信息,理想汽车将在7月内为用户推送全自动AES和全方位低速AEB功能。
什么是AES功能?理想汽车解释为“自动紧急转向功能”。
在车辆行驶速度较快时,主动安全系统的反应时间极短,在部分情况下即使触发AEB,车辆全力制动仍无法及时刹停。此时,AES功能将被及时触发,无需人为参与转向操作,自动紧急转向,避让前方目标,有效避免极端场景下的事故发生。
而低速AEB功能则主要针对泊车和低速行车场景。在复杂的地库停车环境中,立柱、行人和其他车辆等都会增加剐蹭风险,该低速AEB能够识别前向、后向和侧向的碰撞风险,并及时紧急制动。

诺贝尔奖得主丹尼尔·卡尼曼有一套快慢系统理论,人的思考分为快系统、慢系统。
快系统,即系统1,善于处理简单任务,是人类基于经验和习惯形成的直觉,足以应对驾驶车辆时95%的常规场景。
慢系统,即系统2,是人类通过更深入的理解与学习,形成的逻辑推理、复杂分析和计算能力,在驾驶车辆时用于解决复杂甚至未知的交通场景,占日常驾驶的约5%。
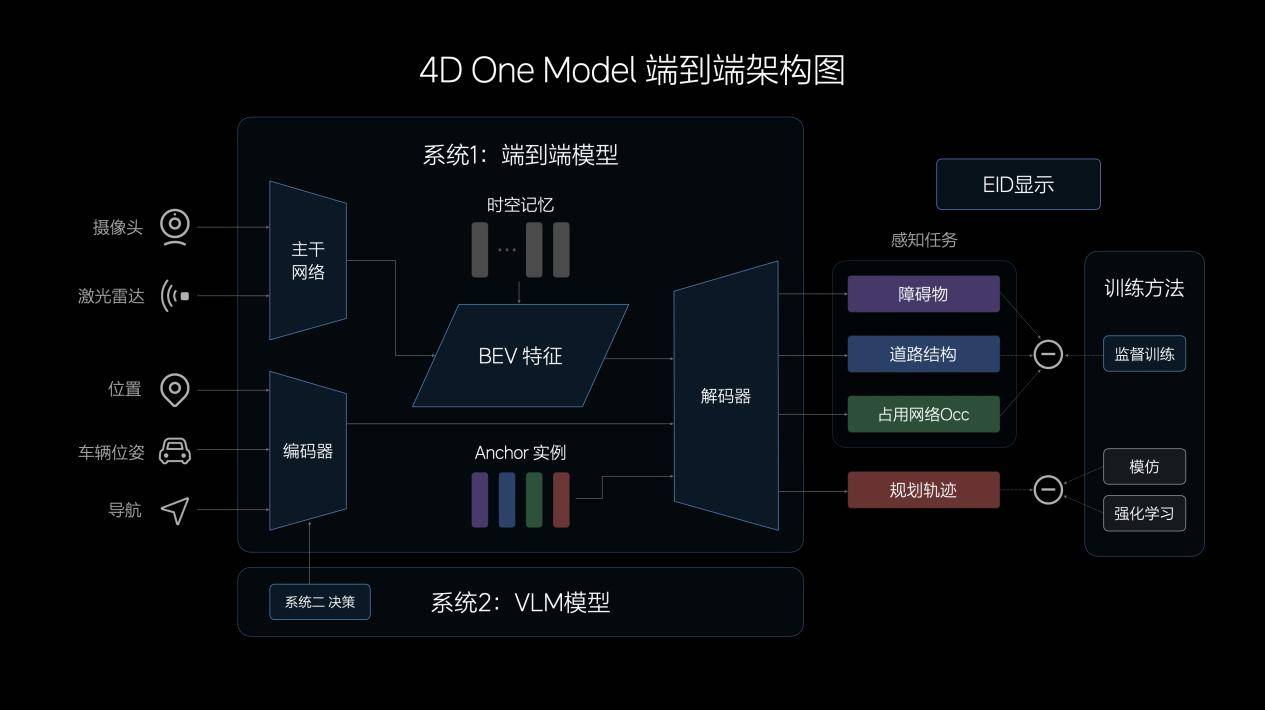
理想汽车自动驾驶算法架构,就是基于快慢系统理论形成的:系统1由端到端模型实现,特点是高效、快速,由端到端模型接收传感器输入,并直接输出行驶轨迹用于控制车辆;系统2由VLM视觉语言模型实现,在接收传感器输入后,经过逻辑思考,输出决策信息给到系统1。
这就形成了快与慢的配合,智驾系统更接近于人的思考习惯。

先说什么是端到端模型?
端到端模型的输入,主要由摄像头和激光雷达构成。这相当于是多传感器的配合,那么,该信息特征经过CNN主干网络的提取、融合后,再投影至BEV空间。为提升模型的表征能力,理想汽车设计了记忆模块,兼具时间和空间维度的记忆能力。
另外,在模型的输入中,理想汽车还加入了车辆状态信息和导航信息,经过Transformer模型的编码,与BEV特征共同解码出动态障碍物、道路结构和通用障碍物,并规划出行车轨迹。
同时,由于中间没有规则介入,因此端到端模型在信息传递、推理计算、模型迭代上均具有显著优势。
所以,在实际驾驶中,端到端模型可以展现出更强大的通用障碍物理解能力、超视距导航能力、道路结构理解能力,以及更拟人的路径规划能力。
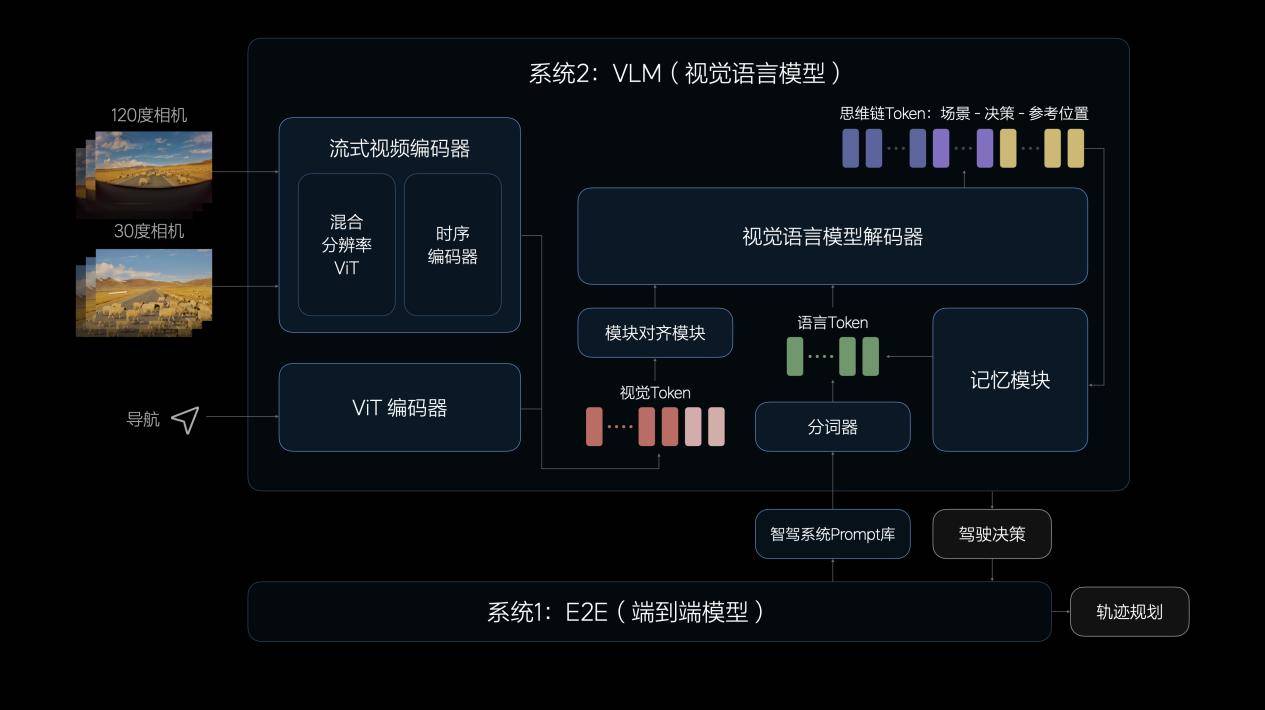
再说什么是VLM视觉语言模型?
VLM视觉语言模型的算法架构由一个统一的Transformer模型组成,将Prompt(提示词)文本进行Tokenizer(分词器)编码,并将前视相机的图像、导航地图信息进行视觉信息编码,再通过图文对齐模块进行模态对齐,最终统一进行自回归推理,输出对环境的理解、驾驶决策和驾驶轨迹,传递给系统1辅助控制车辆。
要理解复杂的物理世界,VLM视觉语言模型参数量要达到一定的量级,理想汽车提供了22亿。所以,VLM模型的功能也比较强大,既可以识别路面平整度、光线等环境信息,以提示系统1控制车速,并具备较强的导航地图理解能力,以配合车机系统修正导航,预防驾驶时走错路线。同时,VLM模型还可以理解公交车道、潮汐车道和分时段限行等复杂的交通规则,在驾驶中作出合理决策。
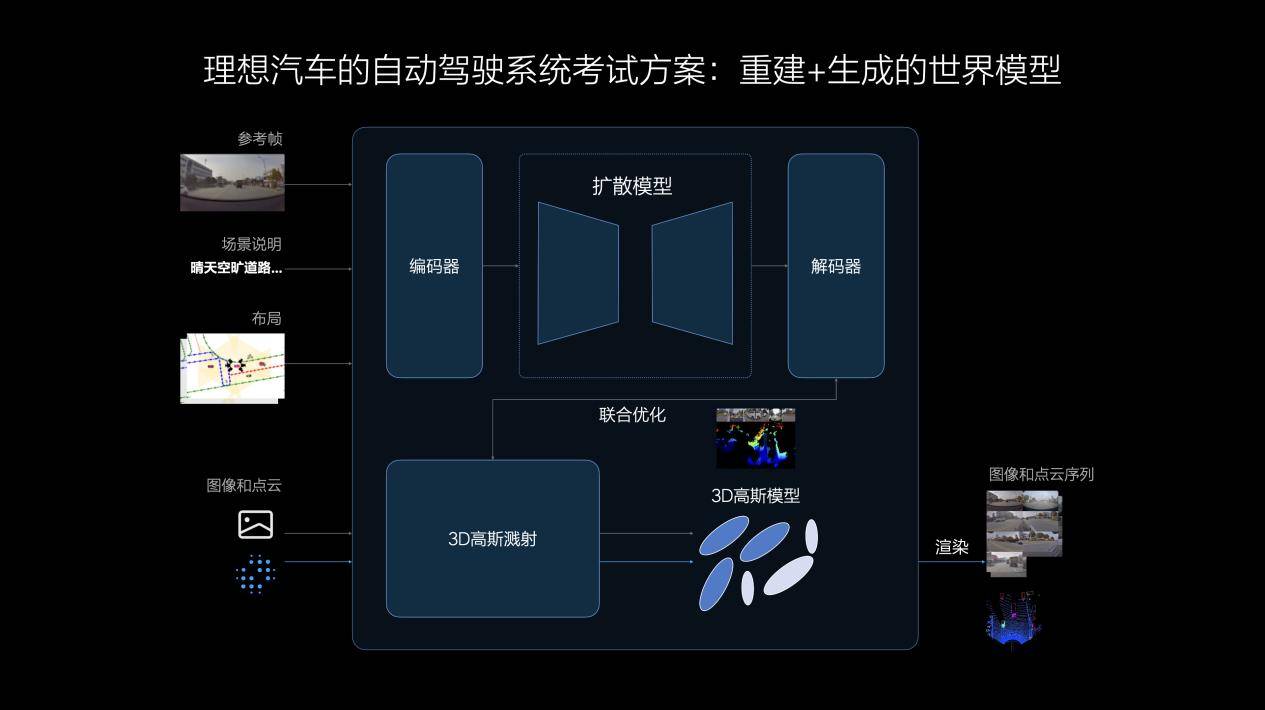
参考理想汽车的说法,他们的世界模型结合了重建和生成两种技术路径,可以将真实数据通过3DGS(3D高斯溅射)技术进行重建,并使用生成模型补充新视角。
在场景重建时,动静态要素将被分离,静态环境得到重建,动态物体则进行重建和新视角生成;再经过对场景的重新渲染,形成3D的物理世界,其中的动态资产可以被任意编辑和调整,实现场景的部分泛化。
相比重建,生成模型具有更强的泛化能力,天气、光照、车流等条件均可被自定义改变,生成符合真实规律的新场景,用于评价自动驾驶系统在各种条件下的适应能力。

理论已经抛出,而实际体验也在路上。或许,理想汽车自此真正找到了解题的密钥,期待他们在实测时的表现了。